deep learning with edge computing a review

#image_title
Recently, there has been a lot of buzz regarding the potential of deep learning inferences on edge devices. With advancements in technology, it has become possible to bring the power of artificial intelligence to the edge of networks, enabling real-time decisions and enhanced capabilities. As we dive deeper into this topic, we came across two insightful articles that shed light on the subject, and we thought it would be worth sharing.
Speeding Up Deep Learning Inference on Edge Devices
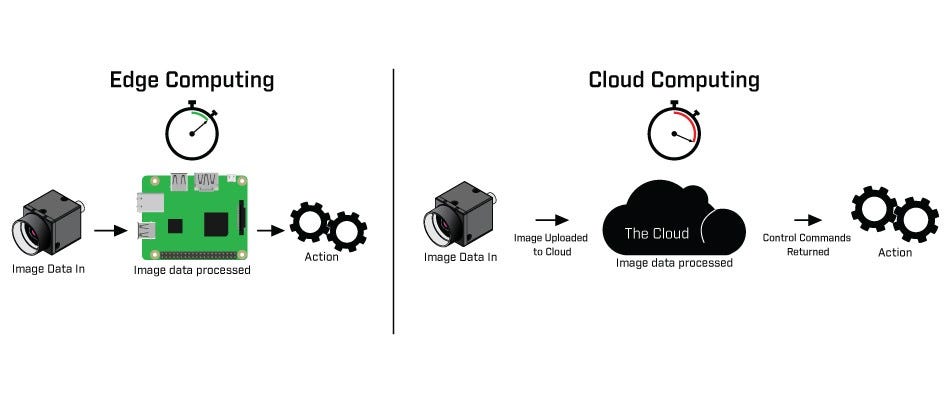
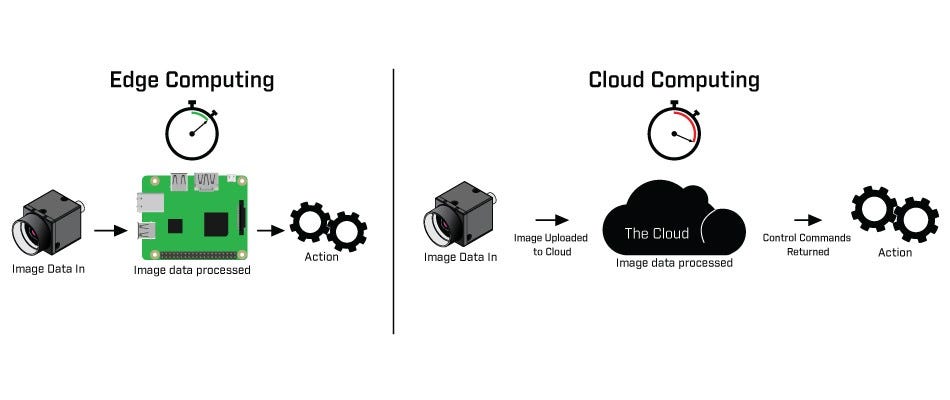
The first article, titled “Speeding Up Deep Learning Inference on Edge Devices,” delves into the challenges and solutions for running deep learning models on edge devices. The author starts by highlighting the growing need for real-time decision-making in various industries, such as healthcare and manufacturing, and how edge devices can help achieve that.

The author then goes on to explain the technical challenges of running deep learning models on edge devices, such as limited computational resources, power consumption, and latency. To overcome these challenges, the article talks about various optimization techniques, such as pruning, quantization, and compression, that can reduce the size and complexity of deep learning models without compromising their performance.
Furthermore, the article discusses the importance of hardware acceleration, such as GPUs and FPGAs, in speeding up deep learning inferences on edge devices. The author explains how these specialized hardware can offload the computationally intensive tasks from the CPU and improve the performance of deep learning models.
Abstract
Deep learning has tremendous potential in enabling real-time decision-making on edge devices in various industries. However, running deep learning models on edge devices comes with several technical challenges, such as limited computational resources, power consumption, and latency. In this article, we explore the optimization techniques and hardware acceleration that can help overcome these challenges and speed up deep learning inferences on edge devices.
Introduction
Artificial intelligence has been transforming various industries, from healthcare to manufacturing, by enabling faster and more efficient decision-making. With the exponential growth of data and the need for real-time decision-making, there is an increasing demand for AI to be deployed on edge devices. Edge devices, such as smartphones, drones, and IoT devices, can bring the power of AI closer to the data source, enabling faster and more efficient decision-making.
However, running deep learning models on edge devices comes with several technical challenges, such as limited computational resources, power consumption, and latency. In this article, we explore the optimization techniques and hardware acceleration that can help overcome these challenges and speed up deep learning inferences on edge devices.
Content
One of the main challenges of running deep learning models on edge devices is limited computational resources. Edge devices may not have powerful CPUs or GPUs to run deep learning models with a large number of parameters. Moreover, running such models can consume a lot of power and reduce the battery life of edge devices. To overcome these challenges, various optimization techniques can be employed.
One such technique is pruning, which involves removing the unnecessary connections or neurons from a deep learning model. Pruning can significantly reduce the size and complexity of a model without sacrificing its performance. For example, a study by Han et al. showed that pruning can reduce the parameter count of AlexNet by 9x without affecting its accuracy.
Another optimization technique is quantization, which involves reducing the precision of the weights and activations of a deep learning model. Quantization can reduce the memory and computational requirements of a model without significant performance degradation. For example, a study by Polino et al. showed that quantization can reduce the memory consumption of a ResNet-50 model by 4x without reducing its accuracy.
In addition to optimization techniques, hardware acceleration can also speed up deep learning inferences on edge devices. Specialized hardware, such as GPUs and FPGAs, can perform matrix operations and other computationally intensive tasks with higher performance and energy efficiency than general-purpose CPUs. For example, a study by Zhang et al. showed that using a GPU can speed up the inference time of a deep learning model on an edge device by up to 10x compared to a CPU.
Conclusion
Running deep learning models on edge devices brings multiple benefits, including real-time decision-making, privacy, and cost-efficiency. However, it also comes with technical challenges, such as limited computational resources, power consumption, and latency. To overcome these challenges, several optimization techniques and hardware acceleration can be employed. Pruning, quantization, and compression can reduce the size and complexity of deep learning models without sacrificing their performance. Specialized hardware, such as GPUs and FPGAs, can offload computationally intensive tasks from CPUs and improve the performance of deep learning models. Overall, the advancement of deep learning inferences on edge devices can significantly impact various industries and lead to new use cases and applications.
Source image : www.einfochips.com

Source image : www.mariner-usa.com
Source image : www.kdnuggets.com

